
1 引 言
炼钢过程是一个非常复杂的高温、多相的物理化学过程,其间存在很多难以定量的因素,建立准确的数学模型非常困难,既使建立了模型,求解难度也大,不能随着工况的改变而自动调整。这都加大了对炼钢过程实现有效控制的难度,已经跟不上时代发展的需要。由于人工神经网络具有较快的学习特性和逼近任意非线性映射的能力,非常适合应用于涉及多因素、复杂过程的控制领域。近二十年来,神经网络的应用在不断扩大,尤其是解决复杂的工业问题。本研究是应用神经网络对炼钢进行终点成分的估计,从而控制过程,改善作业工序、降低原料消耗和提高钢的质量。
在炼钢的过程中,要对钢水终点成分进行估计,再根据成分的含量标准,决定成分的添加量。本研究对象是终点Cr估计模型。Cr成分的主要来源是熔化的原料矿石,但部分原料矿石含有不定量Cr,并且波动性很大,如混合废料(Mixed scrap)含Cr0.9%~5.0%,并且Mixed scrap占“原料矿石”的1/3。另外,取样的检测误差大,主要原因是原料的不充分熔化,测量仪器的偏差和许多随机因素,且各因素之间存在着非线性的关系,这给传统估计系统造成极大的困难。Multon process technology Ltd提供的数据显示,即使通过4~6次采样、评估,Cr的测量值往往低于真实值,终点Cr含量仍然是超出或接近标准的上限。本研究的目标是只通过两次采样,就可以准确估计终点Cr含量,减少多余Cr的加入,从而提高劳动生产率,降低生产成本,提高产品质量。
2 RBF神经网络算法
RBF网络是径向基函数网络,与BP网络都有很强的函数逼近能力,但是BP网络有其自身的弱点,例如存在局部极小问题、学习算法收敛速度慢、收敛速度与初始权值有关以及网络隐层节点个数尚没有理论指导等。相比之下,RBF网络是一类结构简单、性能优越、具有局部逼近能力的神经网络。RBF网络是只有单个隐层的三层前馈神经网络。设网络的输入节点数为n,隐层节点为m,输出节点数为1。
RBF网络的输入为 ,则网络的输出为:
式中ω0∈R—偏置项;
ωj∈R(j=1,2,,m)—隐层到输出层的权值;
Φ(·)—径向基函数;
‖·‖—欧氏范数;
Cj∈Rn—网络的中心。
径向基函数Φ(·)有三种类型:薄板样条函数、高斯函数和RMQ函数。本研究选取高斯函数:
RBF网络的算法比BP算法复杂性要高,分两步进行:输入层到隐层采用无教师指导的聚类方法训练,以确定网络中心向量和半径,常用的是K-均值算法和模糊聚类方法;隐层与输出层之间的权值调整采用有教师指导的算法,以确定权重向量,例如采用递推最小二乘方法等。还有其它的训练方法,主要有:Mooky-Darken算法、局部训练法、聚类与Givens变换联合迭代法等。由此可见,RBF网络的性能主要取决于中心向量、偏置向量和权重向量的学习算法。
3 RBF神经网络Cr估计模型
图1为Cr估计模型。该估计模型由过程变量的选取、数据预处理、主元分析及RBF神经网络的估计四部分组成。过程变量的选取尽量包含所有影响Cr含量的因素;然后,对这组变量进行主元分析,去除对Cr含量影响小的变量,保留影响大的变量,从而压缩数据,简化RBF网络的结构以提高网络的稳定性和收敛性。RBF 神经网络是通过对过程变量的学习,调整网络的参数和结构,得出Cr估计模型。由于神经网络以样本数据为依据,对于不同训练参数,可得到不同的网络模型。因此,上述模型其实是给出一类过程的网络结构,可以应用于各种不同的场合。
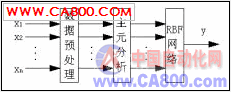
图1 Cr估计模型
3.1 过程变量的选取及其预处理
一般情况下,过程变量的选取遵循两条原则:选取的这组过程变量能够很好地反映整个过程机理;同时,这组变量必须在整个工艺流程过程中容易测量。依据经验及尽量最大地包含影响钢水中Cr含量的因素,选用对钢水进行2次采样的数据,最终选取了13个变量:合金(Alloy)的装入量(X1),固体矿石(Solids)的装入量(X2),铁屑(Turnings)的装入量(X3),通用添加剂(General)的初始质量(X4), Mixed scrap的装入量(X5), 初始Cr%(X6), 炉内余留Cr%(X7), 从加电到采样1的时间间隔(X8), 采样1钢水的温度(X9), 采样1的Cr%(X10), 从采样1到采样2的时间间隔(X11), 采样2钢水的温度 (X12), 采样2的Cr%(X13)。
由于原料装入量的数值一般比较大,而Cr%相对小几个数量级,同时作为网络的输入会造成从隐层到输出层之间权值调整上的困难,影响网络的收敛速度和精度。
3.2 主元分析
在众多过程变量中,有可能存在对Cr含量影响较大的变量;同时,也可能存在对其影响不大,甚至是基本不影响的变量。对结果影响较大的变量,可以加大对其控制,更利于结果的达到;而对于那些对结果影响较小或基本不影响的变量,可以忽略。因此,有必要对数据进行分析,将神经网络技术与统计分析理论结合起来,在预报精度允许的范围内,去掉影响较小的过程变量,减少输入神经元的个数,最大限度的简化网络。
通过上述的数据滤波和标准化处理,最终得到104组数据x(104×13),且:x=[x1,x2, …x13>主元分析法中的降维方法很多,此处是利用对载荷矩阵的分析:即从第一主元所对应的特征向量中选取绝对值最大的系数所对应的变量,然后将此变量从数据集中剔除,再继续用主元分析法分析剩余的数据集合,用同样的判据选择第二个变量。重复此过程。最终,这组过程变量对钢水中Cr含量的影响程度,由大到小依次为:采样一Cr%、Alloy装入量、采样二Cr%、采样二钢水温度、加电到采样一时间间隔、炉内余留Cr%、初始Cr%、 Solids装入量、Turnings装入量、Mixed scrap装入量、采样一钢水温度、General装入量、采样一到采样二时间间隔( x10,x1,x13,x12,x8,x7,x6,x2,x3,x5,x9,x4,x11)。
x8对Cr的含量影响最大,因为x8是原料熔融后第一次采样的Cr含量,本身就是该模型要估计的值,只是测量值与真实值存在误差,才设计该模型对其估计。x4的掺入量很大,但是由于其Cr含量很低,因此对钢水中Cr含量贡献很小,主元分析的结果也恰恰证明了这一点。按主元分析理论中累计方差贡献率达到85%~90%计算,后面几个变量对方差的贡献很小,忽略就可以了。但是考虑到在实际生产中,x2,x3,x4,x5均为原料,它们中的Cr含量是变化的,如对来自不同矿区的矿石,Cr含量存在一定的波动性;同时也考虑到该模型的适应性和通用性,以适应新情况和指导其它生产的需要,将x2,x3,x4,x5保留,去掉x10。
3.3 RBF网络训练及估计结果分析
RBF神经网络的实质是:用神经网络对数据进行函数逼近或者数据拟合问题,在过程变量与Cr含量之间建立映射关系,从而实现对Cr含量的估计。该网络包括两个阶段:训练阶段和估计预测阶段。如图2所示。

图2 RBF神经网络的训练和测试流程
将上面分析的结果:x′=[x1,x2, x9,x11,x12,x13>作为RBF网络的输入,RBF网络的输出y是原料熔融后的钢水Cr含量,这个值是由测量终点Cr含量减去每次采样后的Cr加入量。从104组数据中任选80组数据作为训练集,用剩余的24个样本作为测试集。在本实验中,利用Matlab 提供的newrb( ) 和sim( ) 函数分别来设计径向基函数网络和仿真。 Newrb( ) 函数的优点是可以在学习过程中自适应地调整RBF网络隐层节点直至达到目标误差要求。但是该函数所提供的两个参数err_goal (目标误差) 和spread (径向基函数的分布) 的取值直接影响到网络的拟合和泛化能力。这里,采取动态方式改变这两个参数,以测试集的网络估计值与测试集目标值的最小MSE为中止条件,并且这时的网络泛化能力最强。当err_goal为10e-154, spread为1.64时,网络的性能最佳,这时网络的输出认为是标准化后的数据,经式(2)逆转化后的数据才是真正的预测值(均值1.19,标准差0.23)。图3为模型估计值与测试集目标值的对比曲线。
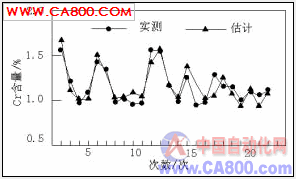
图3 Cr的模型估计值与实验测量值对比
从图3中可以看出,测试集样本17和样本19的相对误差较大,分别是24.84%,18.21%。对104个样本进行整体分析,发现这种类型样本数目很少,说明神经网络没有很好地学习到这种类型样本的规律。由于样本数不足而导致的相对误差较大,并不能说明神经网络的学习能力差,将其抛除。在实际生产中相对误差一般控制在10%以内,该模型的预测准确率为91%。拟合精度能够满足实际生产的要求。
4 结 论
结合应用实例就神经网络技术与实际生产相结合做了探讨,实验表明:估计模型可以在大大减少采样次数的情况下,准确地预测出Cr含量。在实际生产控制过程中,该应用可以为进一步的过程控制提供依据,简化工序,节省人力物力,降低耗能等提供有益的帮助,对生产很有指导意义。模型具有一定的推广能力,可以应用于估计和控制钢水中其它的成分和炼钢的过程变量。
(转载)

