
1 引言
在工业企业信息化过程中,随着关系数据库应用的局限性不断被发现,实时数据开始逐步使用。与关系数据库相比,在工业企业中,生产数据的描述相对简单,但其点数非常多,导致了实时数据库和传统的关系数据库有不同的侧重点。实时数据库在快速处理大量简单生产数据,具有很大的优势。本文的工作建立在已经搭建的基于工业以太网和can总线的中小型现场总线控制系统fcs(fieldbus control system)硬件平台上,参考了开源内存数据库fastdb的实现机制,开发环境是vc++ 6.0。
2实时数据的概念和模型
实时数据库系统的功能特性与实时应用的语义紧密相关,必须首先明确其性质与要求,进而确定rtdbs的设计目标、功能、特性、系统模型。这种应用往往有下列特性:数据时效性(最主要的区别);测点数量多(每秒内要处理大量的数据);存取速度快;数据存贮量(临时存储大量的数据);数据之间的约束关系简单。因此面向实时应用时候可以将数据库理论中的部分功能弱化而将部分功能强化。例如,弱化表之间的关系描述;弱化了数据库理论中的事务处理逻辑等等,舍弃了关系数据库中的触发器,存储过程等高级功能,实时数据库弱化这些功能,用以实现高效的数据插入和查询功能。历史数据库和实时数据库系统主要表现在数据和事务的时间特性上。一个实时数据对象可以抽象为一个三元组:d其中data为数据对象标识,分量dv为数据的当前状态或值(value);dotp是数据的观测时标(observation timestamp),devi是数据的外部有效期(external validateinterval),即自dotp算起,dv的有效性的时间长度。具体应用中实时数据结构模型根据具体的设计需求,在这三元组上进行扩展,还包含其他属性。
3 实时数据库系统功能和结构图
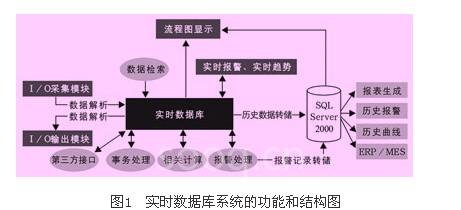
实时数据库在系统中处于中枢环节,数据采集、计算、传输、显示和存储都需要实时数据库的相应功能来支持。通过i/o采集模块获取的现场数据经过程序解析后得到实时数据库可以识别的位号名和过程值。在写入实时数据库的时候会进行量程变换、参数补偿、滤波和累积等组态信息进行计算和各种报警处理,然后将采集到的数据写入实时数据库对应的i/o点变量中。模拟量输出(ao)和数字量输出(do)在实时数据库中经过解析之后,生成传输协议指定的格式通过i/o输出模块发送到主控卡。以上是数据的大体流程,如果这个过程中数据结构定义不完善,就会大大影响系统的效率,因此定义合理的数据结构使数据分发过程快速地完成是提高系统实时性的主要方法之一。系统中既有现场控制站的i/o数据,也有系统的内部变量,变量类型有整型、布尔型、浮点型,为了方便处理,对所有点进行抽象,提出一个统一的实时数据模型,本文中实时数据对象结构定义如下:
class crtrecord {public:char* psztagname; //位号的名称long tagid;
//位号idshort tagtype; //位号类型float pv; //采样值float pvpre;
//上次采样值time_t lsampletime0; //上次采样时间time_t lsampletime;
//本次采样时间time_t lvalidateinterval; //数据有效期bool btransrange;
//是否量程变换float feuhi; //量程上限float feulo; //量程下限float fpvrawlo;
//原始据上限float fpvrawhi; //原始数据下限bool balarming;//是否处于报警状态bool
balarmen; //报警开关float falarmdb; //报警死区bool bhialarmen;
//高限报警bool bhhalarmen; //高高限报警bool bllalarmen; //低低限报警bool
bloalarmen; //低限报警float fllalarmvalue; //报警值int nllprio;
//低低限报警级别float floalarmvalue; //低限报警值int nloprio;
//低限报警级别float fhialarmvalue; //高限报警值int nhiprio; //高限报警级别float
fhhalarmvalue; //高高限报警值int nhhprio; //高高限报警级别bool baccumulate;
//累积开关int ntimecoeff; //时间系数int nunitcoeff; //单位系数bool
bfilter; //是否滤波int nfilterconst; //滤波常数bool bsqrt;
//是否开方int nsigcutthreshold;
//小信号切除阈值}这样定义的数据结构可以方便的完成各种计算和报警操作,比如进行量程转换直接就可以使用这个实时数据对象的量程上下限和原始数据上下限字段进行计算,模拟量位号的变化率报警也可以根据本次采样值和上次采样值的关系推导出来。监控程序如流程图显示、实时趋势图、实时报警等要频繁的从实时数据库检索实时数据,因此实时数据库要支持多线程访问。这样就必须处理好并发控制和事务调度,这也是设计实时数据库的难点。实时数据库还要提供第三方接口,可以方便和其他的程序进行通讯。图1是组态软件实时数据库相关的功能和结构图,实时数据库起到一个核心的作用。
4事务处理和并发控制
事务是并发控制的基本单位,保证事务原子性、一致性、隔离性、持久性(acid)才能确保数据库从一种状态转移到另一种状态。隔离性定理表明,只要每个读写事务的操作对象与其他写事务的操作对象能相互隔离,事务就可以完全隔离的并发执行。而且在实时数据库中事务有定时限制的特性,系统的正确性不仅依赖于逻辑结果,而且依赖于逻辑结果产生的时间,因此必须对并发操作进行合理调度。事务可串行化是实现事务调度的目标,严格的两阶段锁兼顾并发度又可以避免死锁,因此可以用来实现事务的可串行化。两阶段锁的封锁类型有两种:排他锁(exclusive locks,简称x锁,又称为写锁)和共享锁(share locks,简称s锁,又称为读锁)。两阶段锁是指事务的执行分两个过程:第一阶段是获得封锁,在这个阶段,事务可以申请任何数据项上的任何类型的锁,但是不释放任何锁,这一阶段又称为扩展阶段。第二阶段是释放封锁,事务释放他申请的全部封锁,不再申请任何封锁,这一阶段又称为收缩阶段。封锁序列如图2所示。

图2 封锁序列
达到最大的事务吞吐量和最短的事务平均响应时间是实时数据库追求的目标,合理设计锁粒度可以提高数据库并发的效率。在实时内存数据库中,事务获得锁的开销与处理数据的开销相当,所以锁开销对事务运行的速度的影响不可忽视。使用细粒度锁可以提高并发性,但在冲突较低时,并发能力对吞吐量几乎没有影响。如果这时冲突较低,将细粒度锁换成粗粒度锁会减少锁开销。所以,为了在保证并发度的前提下减少事务加锁开销,应该尽量使用粗粒度的锁,本文就是采用粗粒度锁,加锁和解锁都是数据库级别。参考fastdb的实现方式,在本程序设计中数据库的访问方式有如下三种情形,使用一个共用体来表示:enum dbaccesstype {dbreadonly, dballaccess,dbconcurrentread}。如果某个进程使用dballaccess模式访问数据库,如果该进程使用了insert、update、delete等修改数据的操作,其他进程访问该库的所有操作(包括select)都会被阻塞,直到该操作提交或回滚。如果使用dbconcurrentupdate模式访问数据库,当某个进程对数据进行写操作,同时另外的进程使用dbreadonly或者dbconcurrentread读取数据,不会出现阻塞的情况。
5 实时数据库的接口实现
组态软件的实时数据库要具有开放的第三方接口,可以提供给其他的程序进行数据的读写,例如可以和opc server进行通讯。传统的数据库接口比如odbc和ado都是面向关系型数据库的,对于实时内存数据库不再适合。dde接口虽然常用于以前产品的数据交换中,但是速度是个问题。因此采用com接口,让实时数据库以进程内com服务器(in-process com server)方式对外部提供统一的接口。第三方接口采用api方式和sql语法方式。使用api方式可以获得更高的存取速度,而使用sql语法需要对sql进行解析,这样就会影响系统的处理速度,当前只实现了几种常用的sql语法解析,考虑到终端用户的需要,故同时提供这两种接口方式。下面是实时数据库常用的两个接口函数原型:stdmethod(setpvfromtagn-ame)(/*in]*/ bstr *pbstrtagname, /*in]*/ short tagtype, /*in]*/float value); //通过位号名更新实时数据stdmethod(getpvfromtag -name)(/*in]*/bstr *pbstrtagnam -e, /*in]*/ short tagtype, /*out]*/ float*pvalue); //通过位号名读取实时数据
6查询处理算法
在组态软件中,存储介质是影响实时性的一个重要因素。实时数据库采用物理内存作为存储区,在内存中完成对数据的实时操作。这样主存数据库就具有了高性能的事务处理能力,因此查询算法也要针对内存访问的特点设计。
6.1算法选择
磁盘数据库系统的典型的索引技术是b-tree索引。b-tree主要目的是减少数据文件的索引查找所需要的磁盘i/o的数量。t-tree是针对主存访问优化的索引技术,是lehman提出的适应于主存数据库系统的索引结构。t-tree是一种一个节点中包含多个索引条目的平衡二叉树,t-tree的时间复杂度为对数ο(logn)。散列法比树访问机制更快速,平均时间复杂度为常数ο(1)。由于hash表应用起来相对简单,维护也比较方便,对实时数据库操作最多的是根据位号名进行的精确查询、更新,因此散列技术是实时内存数据库的首选方案。
6.2算法设计本文
采用带有冲突链的可扩展的hash表,这个表实际上是一个对象指针数组,有一个指针指向冲突链,冲突链元素构成一个后向链表,每一个元素都包含一个指向后一个元素的指针,可以为数值型和字符串型数据创建hash表。为了避免冲突链的增长,hash表可以根据当前的存储状态自动增长,当前在同时满足如下两种情况下会调整hash表的大小:①表中的记录条数比hash表空间大;②hash表中使用的元素数目(即非空的冲突链数目)大于表的2/3。每次hash表都以两倍的大小增加,确切的说hash表大小是2**n-1(从统计学观点来看使用奇数或者素数作为hash表的大小可以减少冲突的机会)。使用散列机制关键在于选择合适的hash函数使得数据项均匀散列避免或减少冲突。本文使用一个非常简单的hash函数h= h*31 + *key++;hash表的索引就是散列码除以hash表的大小所得的余数。采用此hash函数对组态位号名进行散列,经验证,散列的均匀度比较理想。
7实时数据和历史数据的关系
实时数据和历史数据对于组态软件同等重要,分析他们之间的各自特点才能找到一个好的解决方案。历史数据量巨大;历史数据保存的时间长;存储格式简单,没有复杂的关系;以位号名和时间为查询条件;大量的查询都是最近时间段的历史数据;追加多,删除少,修改少,中间插入少。故采用实时数据库和历史数据库相结合的方法可以发挥各自的优点。本软件中使用功能完善的关系数据库sqlserver 2000作为历史数据库。sql server2000具有强大的数据管理功能和较高的效率,可以满足企业上层程序对数据的分析和访问。比如报表的生成,绘制历史曲线,数据挖掘等。利用windows多线程机制,创建了一个单独的线程用于转储历史数据,采用定量转储方式,转储的条件是当内存中的历史数据超过程序中设置的最大值。
8结束语
实时数据库是组态软件的关键部分,在内存中实现实时数据库能满足组态软件对实时性的要求。利用两阶段锁实现并发控制和事务调度,针对内存的特点设计的查询处理算法,使得数据可以满足流程图监控等频繁的数据检索。利用实时数据库简化了组态软件中数据管理,增强了系统的稳定性。
(转载)

